Pandas提供了很多合并Series和Dataframe的强大的功能,通过这些功能可以方便的进行数据分析,下面这篇文章主要给大家介绍了关于python中DataFrame数据合并merge()和concat()方法的相关资料,需要的朋友可以参考下!
merge()
1.常规合并
①方法1
指定一个参照列,以该列为准,合并其他列。
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, on='id')
print(df_merge)
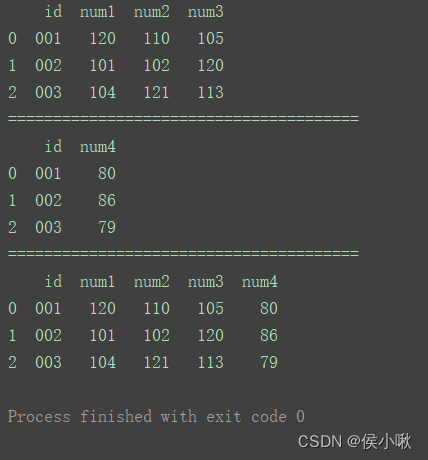
②方法2
要实现该合并,也可以通过索引来合并,即以index列为基准。将left_index 和 right_index 都设置为True
即可。(left_index 和 right_index 都默认为False,left_index表示左表以左表数据的index为基准, right_index表示右表以右表数据的index为基准。)
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, left_index=True, right_index=True)
print(df_merge)
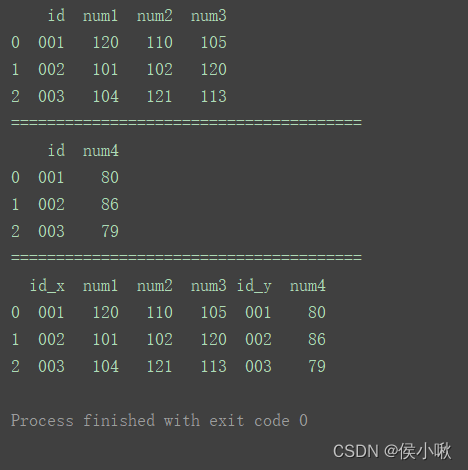
相比方法①,区别在于,如图,方法②合并出的数据中有重复列。
重要参数
pd.merge(right,how=‘inner’, on=“None”, left_on=“None”, right_on=“None”, left_index=False, right_index=False )
参数描述
left左表,合并对象,DataFrame或Seriesright右表,合并对象,DataFrame或Serieshow合并方式,可以是left(左合并), right(右合并), outer(外合并), inner(内合并)on基准列 的列名left_on左表基准列列名right_on右表基准列列名left_index左列是否以index为基准,默认False,否right_index右列是否以index为基准,默认False,否
其中,left_index与right_index 不能与 on 同时指定。
合并方式 left right outer inner
准备数据‘
新准备一组数据:
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
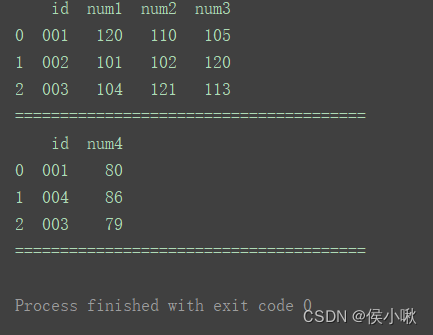
df2 = pd.DataFrame({'id': ['001', '004', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
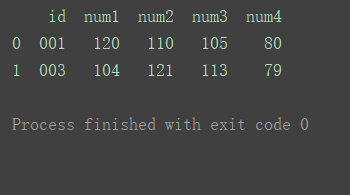
inner(默认)
使用来自两个数据集的键的交集
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
outer
使用来自两个数据集的键的并集
df_merge = pd.merge(df1, df2, on='id', how="outer") print(df_merge)
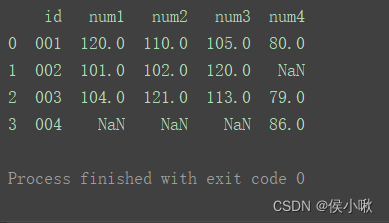
left
使用来自左数据集的键
df_merge = pd.merge(df1, df2, on='id', how='left') print(df_merge)

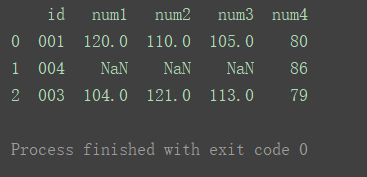
right
使用来自右数据集的键
df_merge = pd.merge(df1, df2, on='id', how='right') print(df_merge)
2.多对一合并
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '001', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
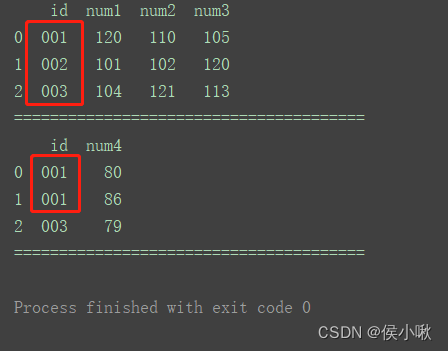
如图,df2中有重复id1的数据。
合并
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
合并结果如图所示:

依然按照默认的Inner方式,使用来自两个数据集的键的交集。且重复的键的行会在合并结果中体现为多行。
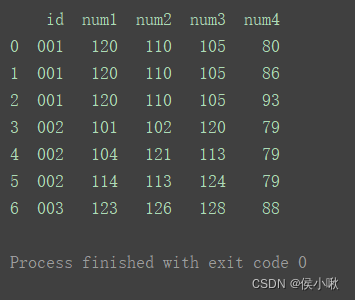
3.多对多合并
如图表1和表2中都存在多行id重复的。
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '002', '002', '003'],
'num1': [120, 101, 104, 114, 123],
'num2': [110, 102, 121, 113, 126],
'num3': [105, 120, 113, 124, 128]})
df2 = pd.DataFrame({'id': ['001', '001', '002', '003', '001'],
'num4': [80, 86, 79, 88, 93]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
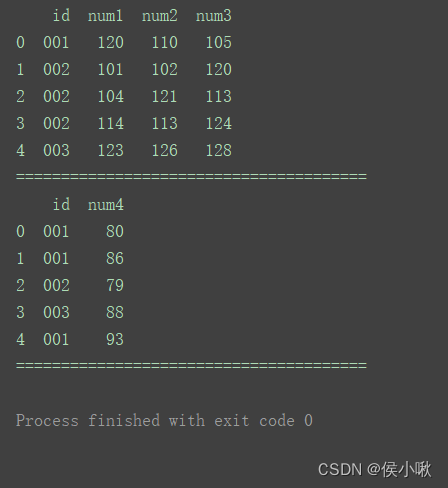
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
concat()
pd.concat(objs, axis=0, join=‘outer’, ignore_index:bool=False,keys=None,levels=None,names=None, verify_integrity:bool=False,sort:bool=False,copy:bool=True)
参数描述
objsSeries,DataFrame或Panel对象的序列或映射axis默认为0,表示列。如果为1则表示行。join默认为"outer",也可以为"inner"ignore_index默认为False,表示保留索引(不忽略)。设为True则表示忽略索引。
其他重要参数通过实例说明。
1.相同字段的表首位相连
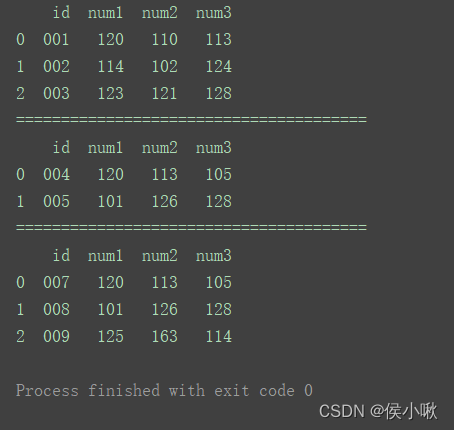
首先准备三组DataFrame数据:
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]})
df2 = pd.DataFrame({'id': ['004', '005'],
'num1': [120, 101],
'num2': [113, 126],
'num3': [105, 128]})
df3 = pd.DataFrame({'id': ['007', '008', '009'],
'num1': [120, 101, 125],
'num2': [113, 126, 163],
'num3': [105, 128, 114]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
print(df3)
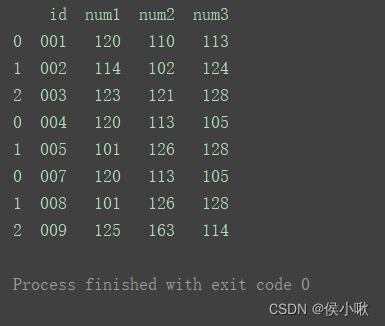
合并
dfs = [df1, df2, df3] result = pd.concat(dfs) print(result)
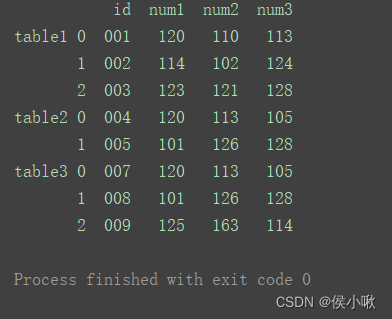
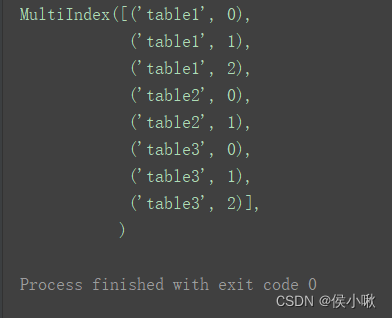
如果想要在合并后,标记一下数据都来自于哪张表或者数据的某类别,则也可以给concat加上 参数keys 。
result = pd.concat(dfs, keys=['table1', 'table2', 'table3']) print(result)
此时,添加的keys与原来的index组成元组,共同成为新的index。
print(result.index)
2.横向表合并(行对齐)
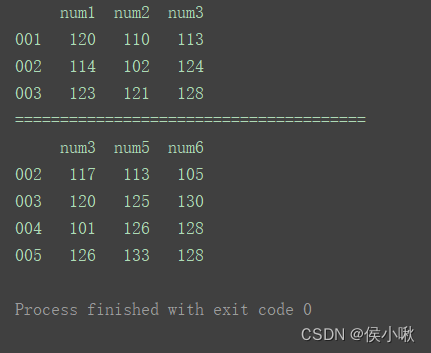
准备两组DataFrame数据:
import pandas as pd
df1 = pd.DataFrame({'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]}, index=['001', '002', '003'])
df2 = pd.DataFrame({'num3': [117, 120, 101, 126],
'num5': [113, 125, 126, 133],
'num6': [105, 130, 128, 128]}, index=['002', '003', '004', '005'])
print(df1)
print("=======================================")
print(df2)
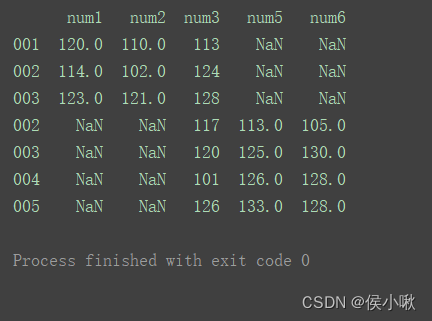
当axis为默认值0时:
result = pd.concat([df1, df2]) print(result)
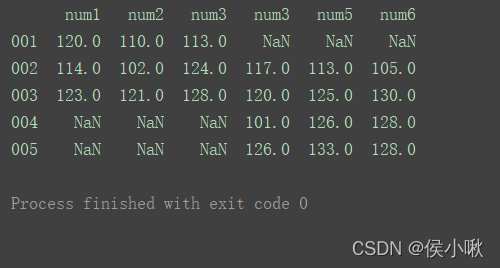
横向合并需要将axis设置为1 :
result = pd.concat([df1, df2], axis=1) print(result)
对比以上输出差异。
- axis=0时,即默认纵向合并时,如果出现重复的行,则会同时体现在结果中
- axis=1时,即横向合并时,如果出现重复的列,则会同时体现在结果中。
3.交叉合并
result = pd.concat([df1, df2], axis=1, join='inner') print(result)
总结
到此这篇关于python中DataFrame数据合并merge()和concat()方法的文章就介绍到这了,更多相关python数据合并merge()和concat()方法内容请搜索蓝色创想以前的文章或继续浏览下面的相关文章希望大家以后多多支持蓝色创想!
 都市极品妖孽
都市极品妖孽 历史名帝被写成渣男,他直接穿书正名
历史名帝被写成渣男,他直接穿书正名 八零悍妇猛搞钱,军官老公爱惨了
八零悍妇猛搞钱,军官老公爱惨了 娱乐:雪藏十年,粉丝终于成年了
娱乐:雪藏十年,粉丝终于成年了 隐门骄龙
隐门骄龙 做了预知梦后,我转头嫁给渣男皇叔
做了预知梦后,我转头嫁给渣男皇叔 盖世圣医
盖世圣医 不羡鸳鸯不羡仙
不羡鸳鸯不羡仙 和蛇妖夫君be后我选择修道
和蛇妖夫君be后我选择修道 风光二婚,渣男前夫急疯了
风光二婚,渣男前夫急疯了 不爱又怎么样
不爱又怎么样 绝世高手张宇
绝世高手张宇 广城的初夏都特别热许雨晴
广城的初夏都特别热许雨晴 虞溪蔷沈泊礼
虞溪蔷沈泊礼 天才萌宝:妈咪只想当咸鱼
天才萌宝:妈咪只想当咸鱼 我穿成了小说里的贫穷路人甲
我穿成了小说里的贫穷路人甲